~/projects/crystalloids
status: completedStage S7 - Crystalloids
Stage d'ingénieur DevOps de 17 semaines chez Crystalloids, à Rotterdam (Pays-Bas), au sein d'une équipe internationale anglophone. Objectif : fiabiliser et automatiser des tâches de monitoring sur Google Cloud Platfrom pour libérer du temps d'ingénierie et renforcer la qualité du suivi des données clients.
~/contexte
Le contexte
Crystalloids est une entreprise néerlandaise spécialisée dans les plateformes data et marketing basées sur Google Cloud, reconnue comme Google Cloud Premier Partner - le plus haut niveau de partenariat accordé par Google. L'organisation s'articule autour de trois pôles : DevOps (supervision, monitoring, fiabilité), Software Engineering (développement des pipelines) et FinOps (maîtrise des coûts cloud).
Intégré à l'équipe DevOps, j'ai d'abord pris en main un écosystème GCP dense - console, services managés, logs, projets clients - avant de gagner en autonomie sur les monitoring activities quotidiennes. C'est de cette pratique répétitive qu'ont émergé mes deux projets principaux, tous deux guidés par le même fil rouge : optimiser l'existant par l'automatisation. La sécurité structurait le travail au quotidien : environnements cloisonnés, gestion fine des permissions via IAM et application stricte du principe de moindre privilège, y compris pour les stagiaires.
Tous les noms de clients sont anonymisés (Client A, B, C…) et aucune donnée d'entreprise n'est exposée, conformément aux règles de confidentialité de Crystalloids.
~/projet-a
Projet A - Data Check Optimisation
Un outil d'automatisation du monitoring quotidien des données clients, conçu from scratch et né d'une initiative personnelle.
Le problème
Chaque jour, plusieurs plateformes clients devaient être vérifiées à la main : fraîcheur des données, cohérence des volumes, exécution des pipelines, absence d'erreurs, stabilité des coûts. Ce contrôle était répétitif, mécanique et chronophage - environ une heure par client - tout en restant exposé à l'erreur humaine (seuil mal évalué, oubli, mauvaise interprétation). En élargissant mon périmètre, le besoin d'automatisation est devenu évident.
La solution
Après un premier prototype local, le projet a pris de l'ampleur : concevoir une solution structurée capable d'automatiser tous les contrôles importants, de centraliser les résultats dans une base de données, d'offrir un tableau de bord unique, et de permettre d'ajouter ou désactiver un check sans toucher au code. J'ai défini une architecture cloud-native modulaire, reposant uniquement sur des services managés GCP.
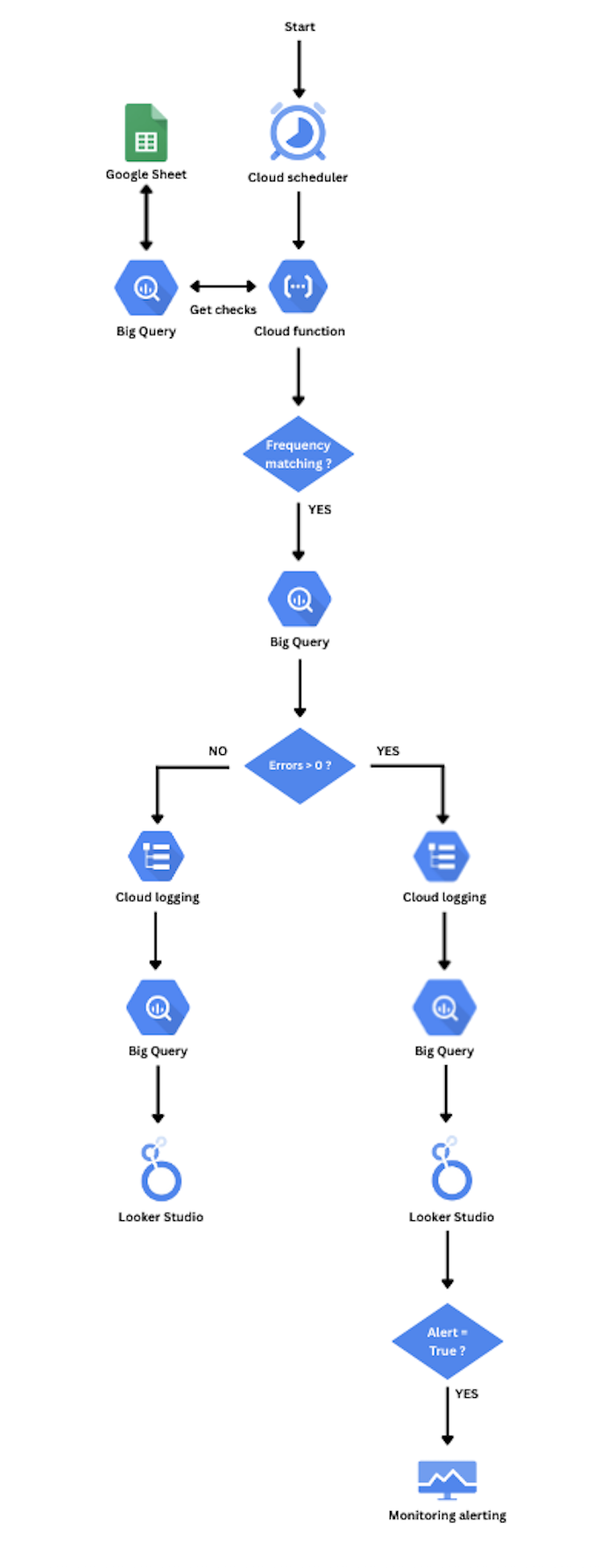
Fonctionnement
La Cloud Function s'exécute chaque matin et déroule les étapes suivantes :
- Lecture d'une Google Sheet de configuration → table BigQuery (liste des checks)
- Filtrage des contrôles actifs du jour selon leur fréquence
- Exécution de chaque requête BigQuery (fraîcheur, volumes, cohérence, valeurs nulles…)
- Calcul d'un statut : OK, FAILED, MALFORMED ou EXECUTION_ERROR
- Historisation des résultats dans BigQuery + Cloud Logging
- Déclenchement d'une alerte si le contrôle est configuré pour
Pour ajouter un contrôle, il suffit d'ajouter une ligne dans la Google Sheet : l'équipe gère ses checks sans intervention de développement. La première version automatisait 19 contrôles pour un seul client.
Le tableau de bord
Le dashboard Looker Studio, conçu de A à Z, est l'interface principale de l'équipe. Pour chaque check, il affiche le client, la table, le type de contrôle, le statut, le nombre d'erreurs et la date d'exécution, avec des filtres par table, date et sévérité.
| table | status | severity | errors |
|---|---|---|---|
| 29_pipeline_durations | FAILED | WARNING | 6 |
| 29_pipeline_durations | FAILED | ERROR | 6 |
| 22_data_consistency | OK | INFO | 0 |
| 14_freshness_check | OK | INFO | 0 |
Sécurité & extension
L'ensemble repose sur deux service accounts distincts (exécution / configuration) aux droits minimaux, Secret Manager pour les identifiants, et un principe de moindre privilège strict : aucune ressource sensible exposée, aucune donnée client transmise hors de GCP. Le système a ensuite été étendu au monitoring des DAGs Airflow : détection automatique des workflows en échec, historisation dans BigQuery et affichage unifié dans le même dashboard.
→ résultat
Temps de monitoring réduit de ~1 h à 5–10 min par client, soit 85 à 90 % de gain de temps.
Résultats centralisés, reporting uniformisé, traçabilité renforcée, architecture réutilisable pour d'autres clients et outil validé puis adopté par toute l'équipe DevOps.
~/projet-b
Projet B - Migration d'un audit de sécurité
Faire passer un audit de sécurité quotidien d'une machine virtuelle vers une architecture entièrement serverless.
Le problème
Un audit de sécurité quotidien vérifiait les rôles IAM d'un client (utilisateurs, service accounts, datasets, tables, buckets, politiques de projet). Il tournait sur une VM dédiée via un cron, avec plusieurs limites : un coût fixe (~30 €/mois), une maintenance lourde (mises à jour OS, snapshots, surveillance), aucune intégration avec l'écosystème serverless de l'entreprise, et un point de défaillance unique - si la VM tombait, l'audit s'arrêtait.
La solution
Migrer l'audit vers une Cloud Function déclenchée par Cloud Scheduler, alimentant cinq tables BigQuery partitionnées (un audit par niveau IAM : projet, datasets, tables, buckets, service accounts), elles-mêmes lues en read-only par un tableau de bord Looker Studio. Le partitionnement par date garantit une historisation propre et des coûts maîtrisés.
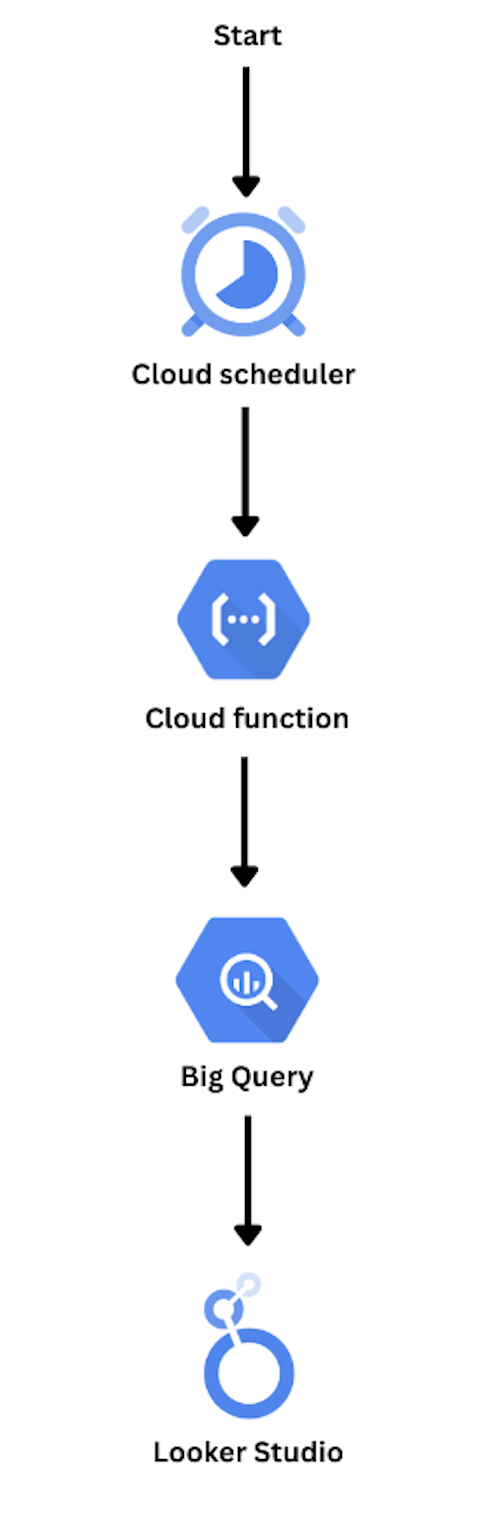
Les étapes de migration
01 Extraction depuis la VM
Connexion SSH à la machine virtuelle et analyse d'un script non documenté (exec_audit.sh, security-audit.py) pour reconstituer la séquence d'exécution et les dépendances.
02 Adaptation au serverless
Réécriture du script pour le modèle stateless de Cloud Run : suppression des chemins locaux, remplacement des accès fichiers par des écritures BigQuery, intégration de Secret Manager et réduction du temps d'exécution pour éviter les timeouts. C'est la partie la plus technique du projet.
03 Déploiement & IAM
Création d'un service account dédié avec un jeu de rôles minimal (least privilege), puis automatisation du déploiement de la fonction.
04 Performances & optimisation
Sur l'environnement de production, le volume de tables provoquait des timeouts. Après concertation avec le responsable sécurité, exclusion des tables trop volumineuses et sans valeur ajoutée pour stabiliser l'exécution.
05 Validation & suppression de la VM
Sortie comparée à l'identique entre la VM et la version serverless, validation par le responsable sécurité, puis suppression définitive de la machine virtuelle.
→ résultat
VM supprimée : 30 €/mois → 0 € et maintenance ramenée à zéro.
Audit fiabilisé (déclenchement automatisé, monitoring intégré), reporting professionnel relié aux tables partitionnées, et architecture réutilisable pour d'autres clients. Une transition concrète d'un système traditionnel vers du cloud-native.
~/mini-projets
Mini-projets complémentaires
En parallèle des deux projets principaux, deux interventions plus courtes ont prolongé la même logique de fiabilisation et de réduction de la dette technique.
Pipeline Jira → BigQuery → Looker Studio
Remise en service d'un pipeline de récupération de tickets Jira tombé en panne : remplacement d'un compte personnel obsolète par un service account sécurisé, diagnostic de l'API avec Postman, et résolution d'une mauvaise configuration IAM côté Jira - jusqu'à un contact direct avec Atlassian. L'occasion de mesurer le coût réel d'un pipeline non documenté.
Cloud Function : correctif + migration Gen1 → Gen2
Correction d'un faux positif (la fonction contrôlait les fichiers de la veille au lieu du jour même), puis modernisation opportuniste vers Cloud Functions Gen2 (Python 3.11, architecture Scheduler → Pub/Sub → Eventarc → Cloud Function, logs détaillés). Résultat : une fonction plus stable, plus lisible et plus simple à maintenir, à finalité métier identique.
~/bilan
Bilan
Ce stage m'a permis de mener des projets DevOps complets en quasi autonomie, de l'analyse à la mise en production, et de monter significativement en compétence sur GCP, Python, SQL et la gestion de projet agile (daily meetings, revues hebdomadaires, tickets Jira), le tout dans un environnement anglophone. Au-delà de la technique, j'en retiens qu'un ingénieur a une vraie valeur lorsqu'il sait proposer, documenter et améliorer durablement l'existant.
Les choix techniques ont aussi eu un effet vertueux sur la sobriété : supprimer une VM allumée en continu au profit d'un modèle pay-per-use et automatiser le monitoring réduisent les ressources mobilisées - la maîtrise des coûts (FinOps) rejoignant souvent celle de la consommation énergétique.
À titre personnel, ce stage a confirmé mon orientation : mettre mes compétences DevOps au service de la cybersécurité, là où l'automatisation et la fiabilisation des processus sont clés (analyse de logs, détection d'intrusion, sécurité offensive).
~/stack